Simplified diagram showing how wspr.live relates to wsprnet.org and WsprDaemon spots and noise
What is wspr.live? wspr.live is a database containing all the spots ever reported to wsprnet.org
Who has created this database? Arne, contactable by email as admin at wspr dot live.
How does wspr.live relate to WsprDaemon? First, the wspr.live database is hosted on a WsprDaemon server. Second WsprDaemon users that upload detailed spots information and noise data now have their data automatically forwarded to tables in the wspr.live database.
What's the technology behind wspr.live? Clickhouse - a column-oriented database that has been optimised for queries by time and by band.
Where can I learn more? You can find an overview at wspr.live, summarised in the simplified diagram below, and Arne's explanation beneath. There's also an extensive set of Grafana visualisations, including WsprDaemon noise and receiver SNR comparison. Phil, VK7JJ, has provided a simple user interface for your own queries to wspr.live with a number of analysis tools preconfigured at the wspr.rocks site.

wspr.live
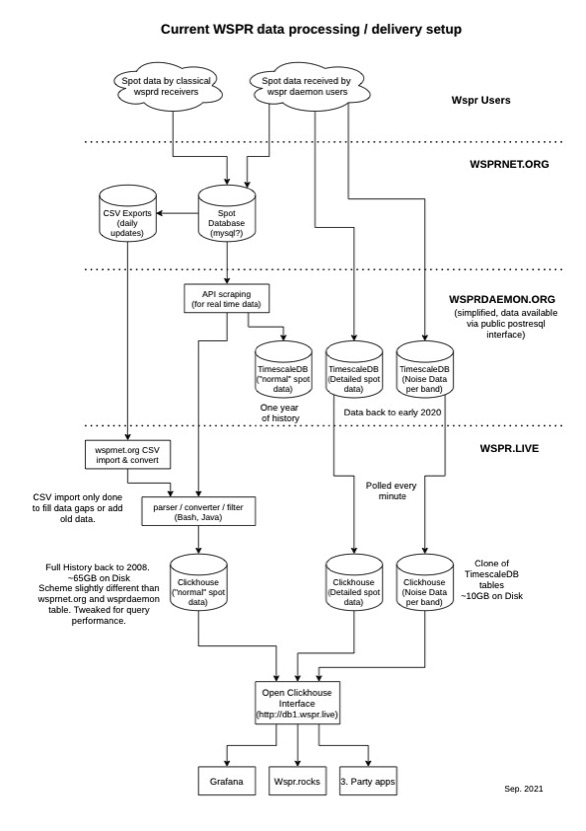
Arne writes:
Unfortunately there seems to be still a misunderstanding of what databases are available. The diagram above shows most of the databases and how they are connected. You might have a look onto it when reading my following description.
First there is the wsprnet.org database where everyone reports their spots. This data is provided as CSV exports updated daily and via an non-public API for live data. Rob has access to this API and uses it to feed all our services with live spots.
The stream of new spots is feed into a TimescaleDB instance on the logs1 and logs2 servers. Since TimescaleDB is based on the row oriented PostgreSQL database it comes with all the advantages and disadvantages of row based storage.
Beause of the nature of the data (not much to normalize, many strings like call signs and locators) a relational database like PostgreSQL is (from my point of view) not the right choice to store spot data. On top of that the database scheme on wsprdaemon.org has some major design flaws which slows down the data processing and adds to the disk space footprint. So Wsprdaemon.org stores and provides wspr history from mis 2020 (my graph states "one year of history" which is wrong) in their public tables because TimescaleDB is not able to handle much more in reasonable time frames. If one would try to add the whole history into TimescaleDB it would take days to import and use most of the 7 TB volume available.
My database on wspr.live uses Clickhouse instead of TimescaleDB. Clickhouse is a column oriented database and designed for exactly the type of data we have: A huge table of data that would not gain much from normalization. On top of that I spent weeks tweaking the database scheme for maximum search performance. Clickhouse also uses clever compression algorithms to highly reduce the storage footprint of the stored columns. So in Clickhouse the whole wspr spot data set going back to 2008 only takes 79 GB of disk space right now (including the extra WsprDaemon tables). Since reading the data is the slowest step in data processing Clickhouse can search way more data in way less processing time.
As shown on the diagram above the spot data is feed into both, Clickhouse on wspr.live and TimescaleDB on wsprdaermon.org. So both databases contain live data: wsprdaemon.org since mid 2020 and wspr.live the full history.
Importing the whole history from the wsprnet.org CSV exports into Clickhouse takes about two hours on the logs1 server. The speed is limited by the download speed of wsprnet.org; Clickhouse can import even faster.
Parallel to that the wsprdaemon noise and spot data are collected by WsprDaemon and also feed into Clickhouse on wspr.live and TimescaleDB on wsprdaermon.org. Both contain the full history.
If you try to run complex queries on the spot data wspr.live is the right choice for 99% of use cases.
The tools by VK7JJ are backed by:
Wspr.rocks is powered by Clickhouse from wspr.live.
wspr.rocks/livequeries/ provides a method of inputting Clickhouse SQL commands.
WsprDaemon
Robust decoding and reporting for WSPR FST4W FT8 FT4 WWV WWVH CHU